Venari
Version 6.1 - June 2026

Venari 6.1 is here! This release is dedicated to scale, robustness and self-tuning, focused on helping large scans finish faster and with fewer interruptions. The scan engine now tunes itself to each target — increasing concurrency when an application has headroom and backing off when it starts to struggle — and it recovers on its own from browser crashes, transient slowdowns, and infrastructure hiccups, keeping long-running scans on course.
This release also delivers the largest expansion of vulnerability detection in Venari's history. A new rule evaluation engine supports a broader rule library, three brand-new attack engines (JWT, web cache poisoning/deception, and HTTP request smuggling), and active technology fingerprinting that keeps checks aligned with the application being scanned. Every rule is validated against the Venari Firing Range, our purpose-built set of vulnerable targets, and a major false-positive reduction effort makes the resulting findings cleaner and easier to trust.
Smart fuzzing keeps scans lean by recognizing low-value requests, inert directories, and non-injectable parameters before they consume scan time. New onboarding paths bring ServiceNow scoped applications and Bruno API collections into scope, and Managed Scans give SaaS customers a simplified, guided way to onboard and run scans while Venari handles the real scanning under the covers.
For cloud and enterprise customers, 6.1 introduces durable backup and restore, customer-run hybrid job nodes, multi-tenant administration with SSO, and flexible notifications.
The list of feature and enhancement highlights is shown below.
Feature Highlights
- Self-Tuning Scan Performance
- Resilient, Self-Healing Scans
- Smart Fuzzing — Leaner Scans, Same Coverage
- Expanded AppSec Rule Library (and Venari Firing Range)
- Bruno Collection Import
- ServiceNow Scoped-App Scanning
- New Attack Engines: JWT, Web Cache, Request Smuggling
- Tech-Stack Fingerprinting & Rule Targeting
- Scan Notifications — Email, Webhooks, Per-User Subscriptions
- Browser Engine Refresh & 'Full Browser' option for Bot-Blocking Sites
- Substantial False Positive Reduction
- Lower Memory Footprint
- Modernized UI & Interface Polish
- Managed Scans — Simplified SaaS Onboarding
- Customer-Hosted Scan Nodes
- ARM64 Linux Scan Nodes (incl. AWS Graviton)
- Durable Cloud Backup & Restore
- Enterprise Multi-Tenancy & SSO
- Change Log Summary
Self-Tuning Scan Performance
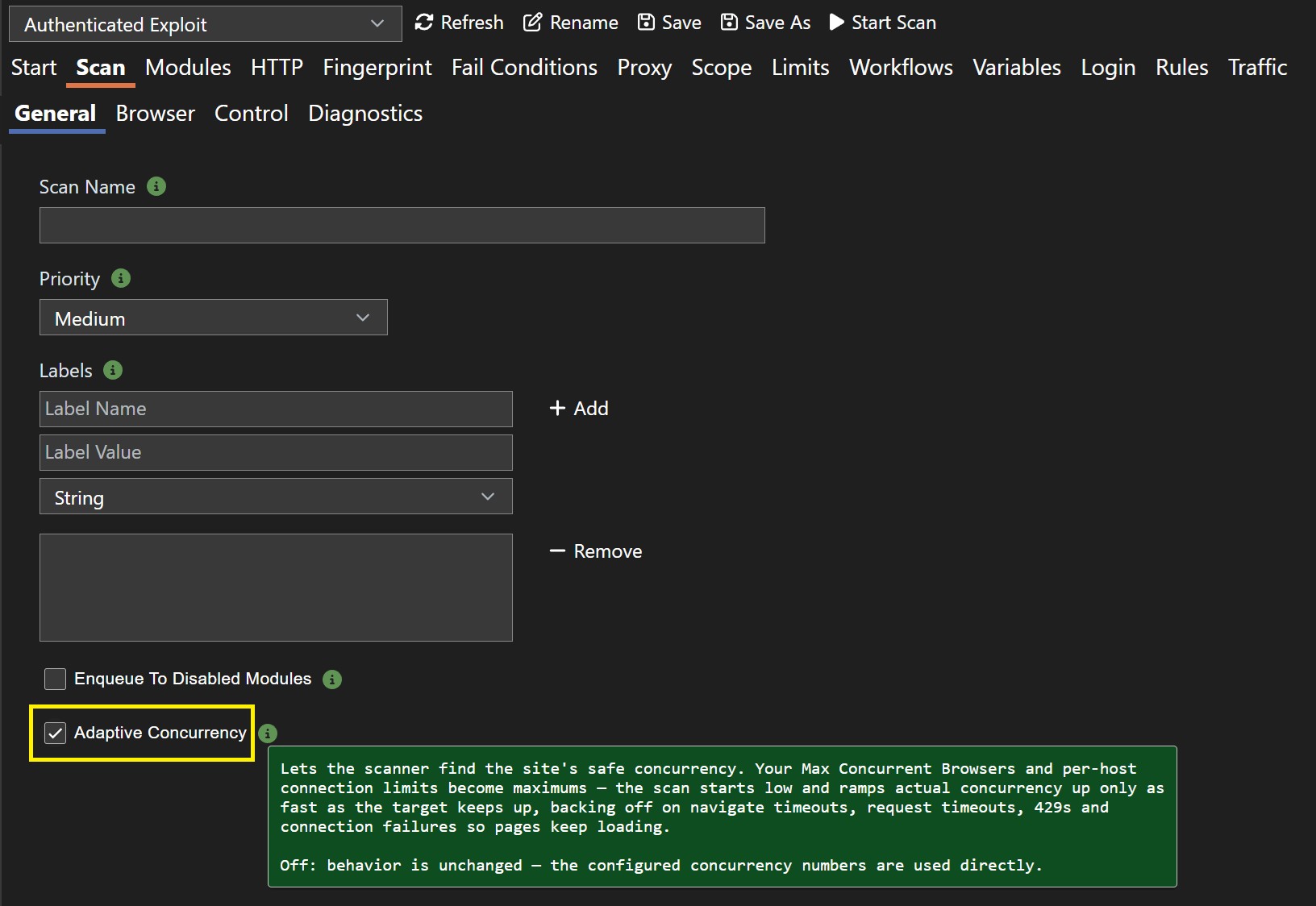
Venari 6.1 can automatically detect the max scan load each target can handle. Instead of sending work at a fixed rate across the entire scan, adaptive, per-origin concurrency monitors how each application origin responds and adjusts request and browser activity independently. Stronger targets get more sustained load, and fragile targets get less pressure before they become overloaded.
When Venari detects signs that a target is overloaded, it backs off, requeues the work, and ramps back up as the site recovers. The result is a better balance between speed and safety: faster scans where there is capacity, fewer overloaded applications, and fewer long scans that lose time because one origin could not keep up. Adaptive concurrency is available as an opt-in scan setting on the Scan | General tab.
Resilient, Self-Healing Scans
Long-running scans keep going when the runtime environment gets noisy. If a Chrome instance crashes or stops responding during browser-driven discovery, Venari detects the failure, removes the bad browser from the pool, cleans up orphaned processes, and continues with a healthy replacement browser. On the HTTP side, the request engine now uses non-blocking I/O for socket reads and TLS handshakes. Bursts of concurrent requests no longer tie up threads waiting on network I/O. This keeps the scanner responsive, even under very high request volume.
Unattended deployments recover without hands-on intervention. On startup, a master node repairs a corrupted internal database automatically instead of requiring manual file cleanup — important for unattended cloud and Kubernetes deployments.
Smart Fuzzing — Leaner Scans, Same Coverage
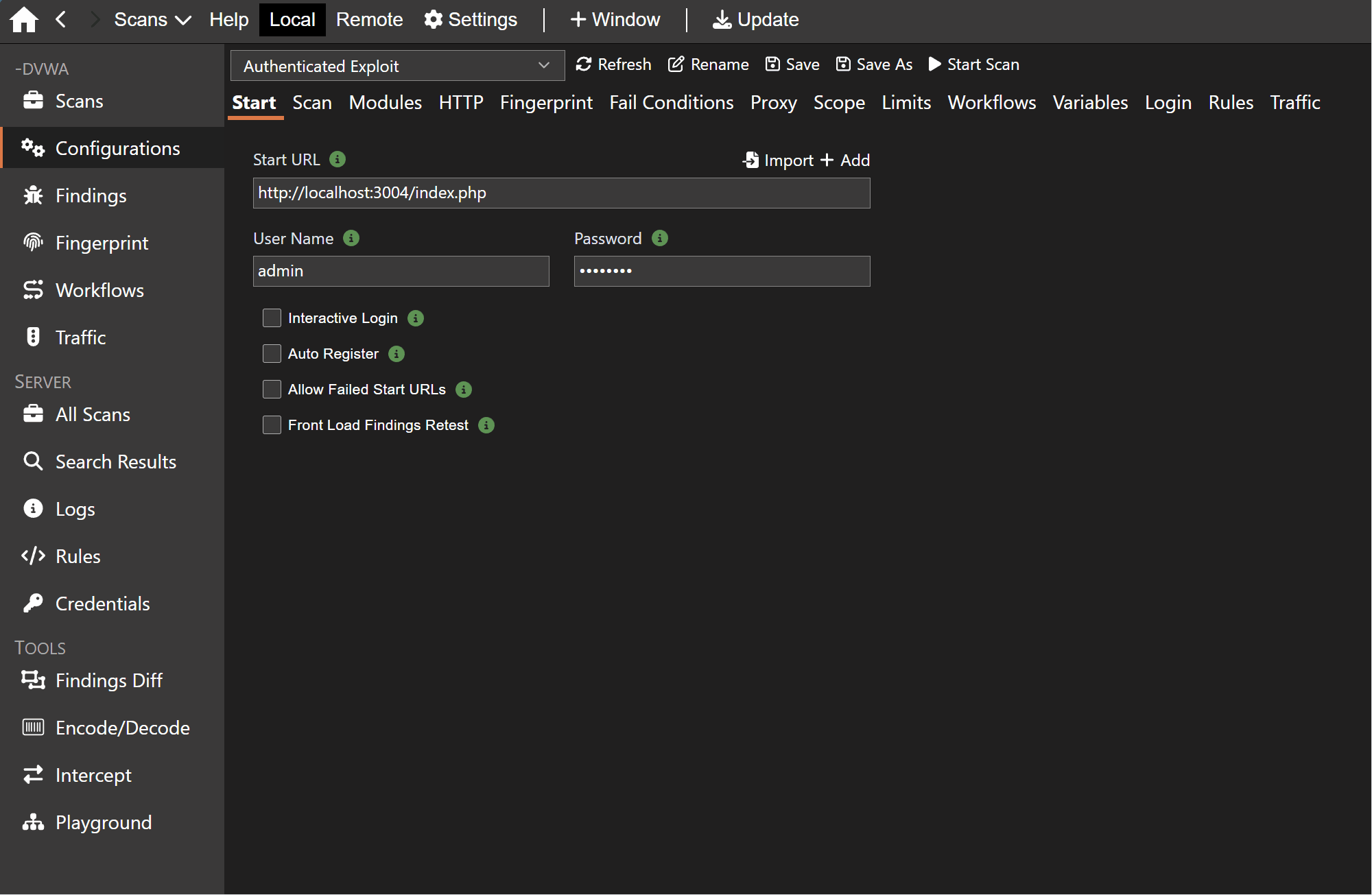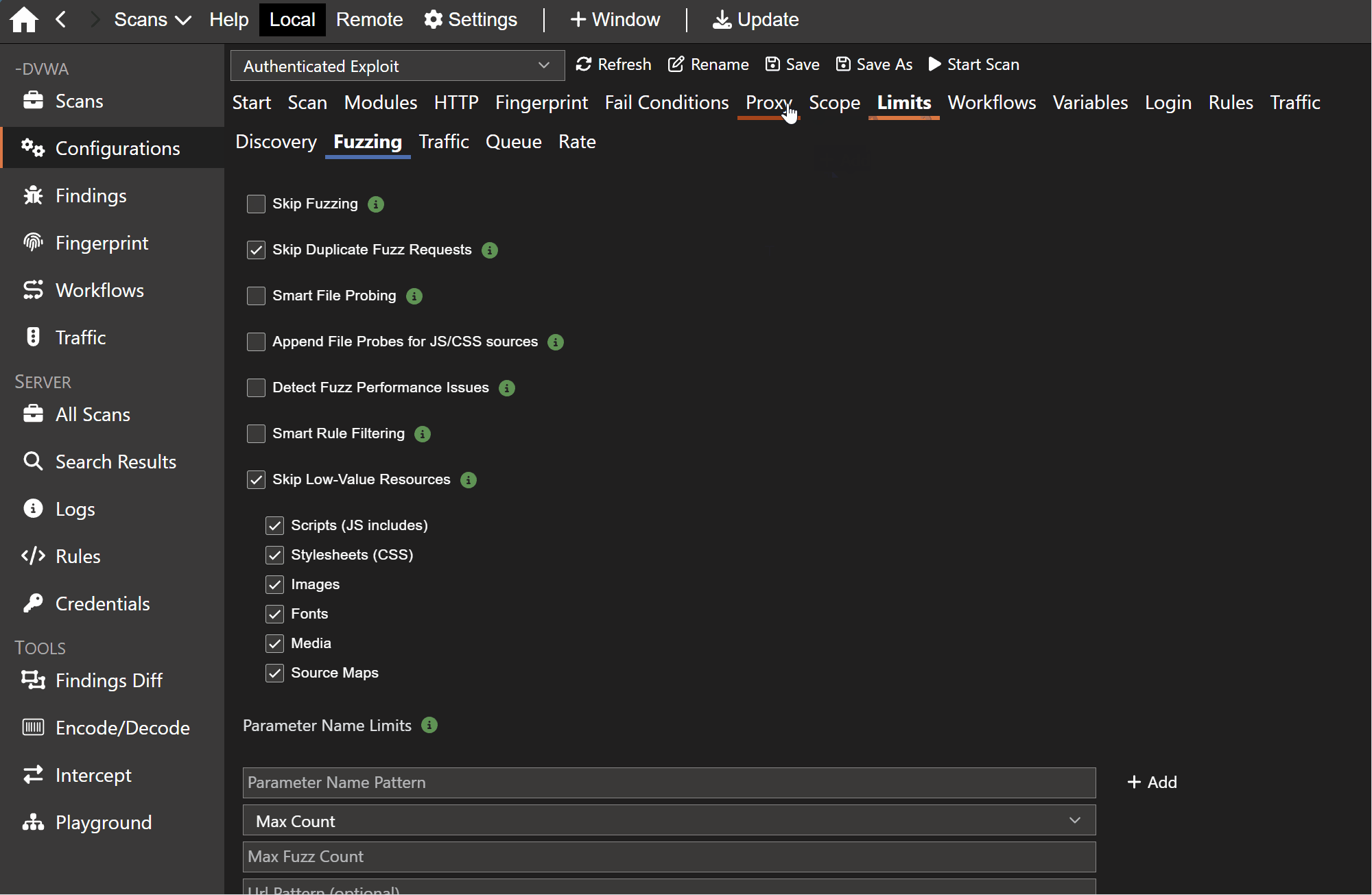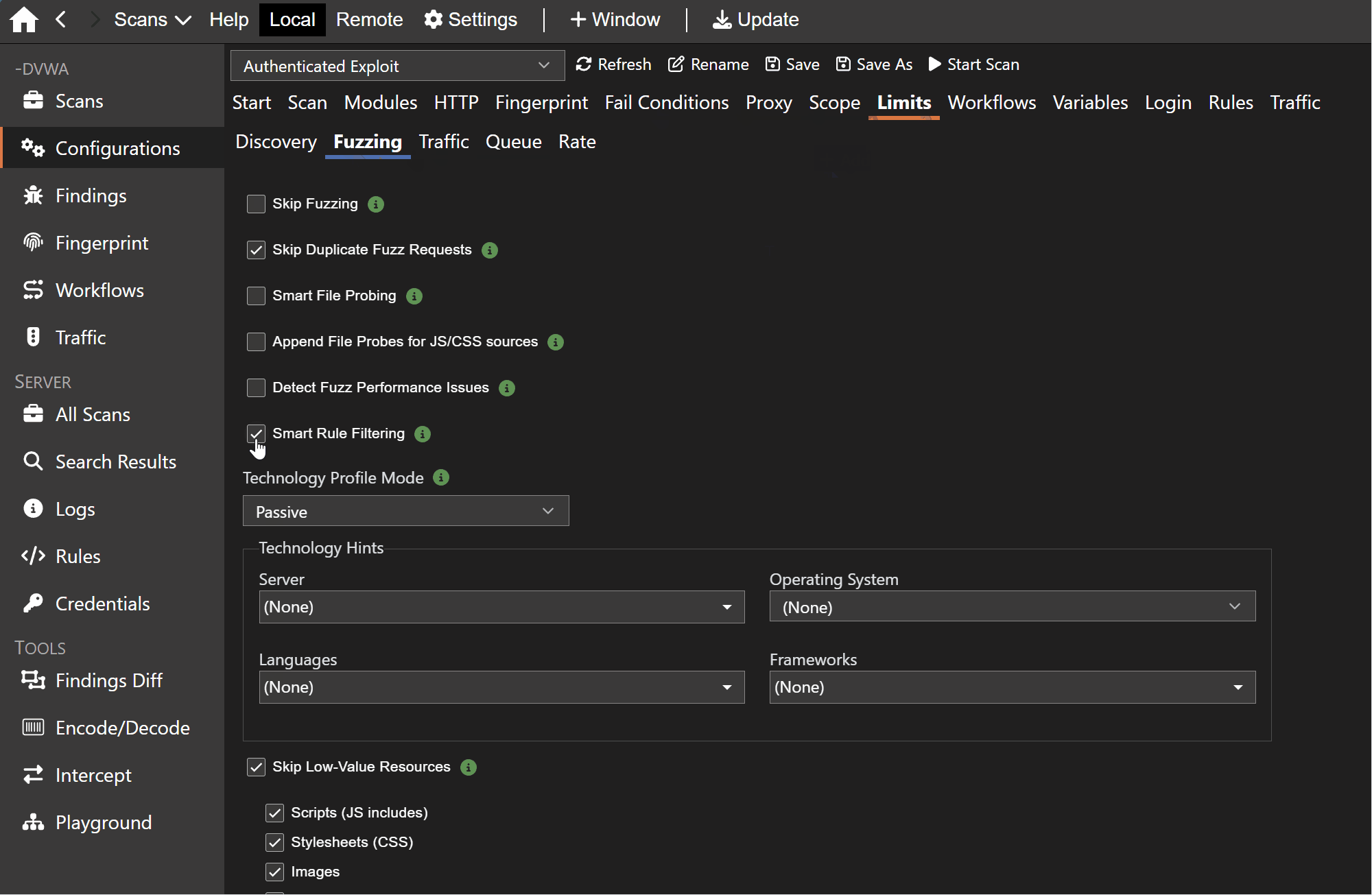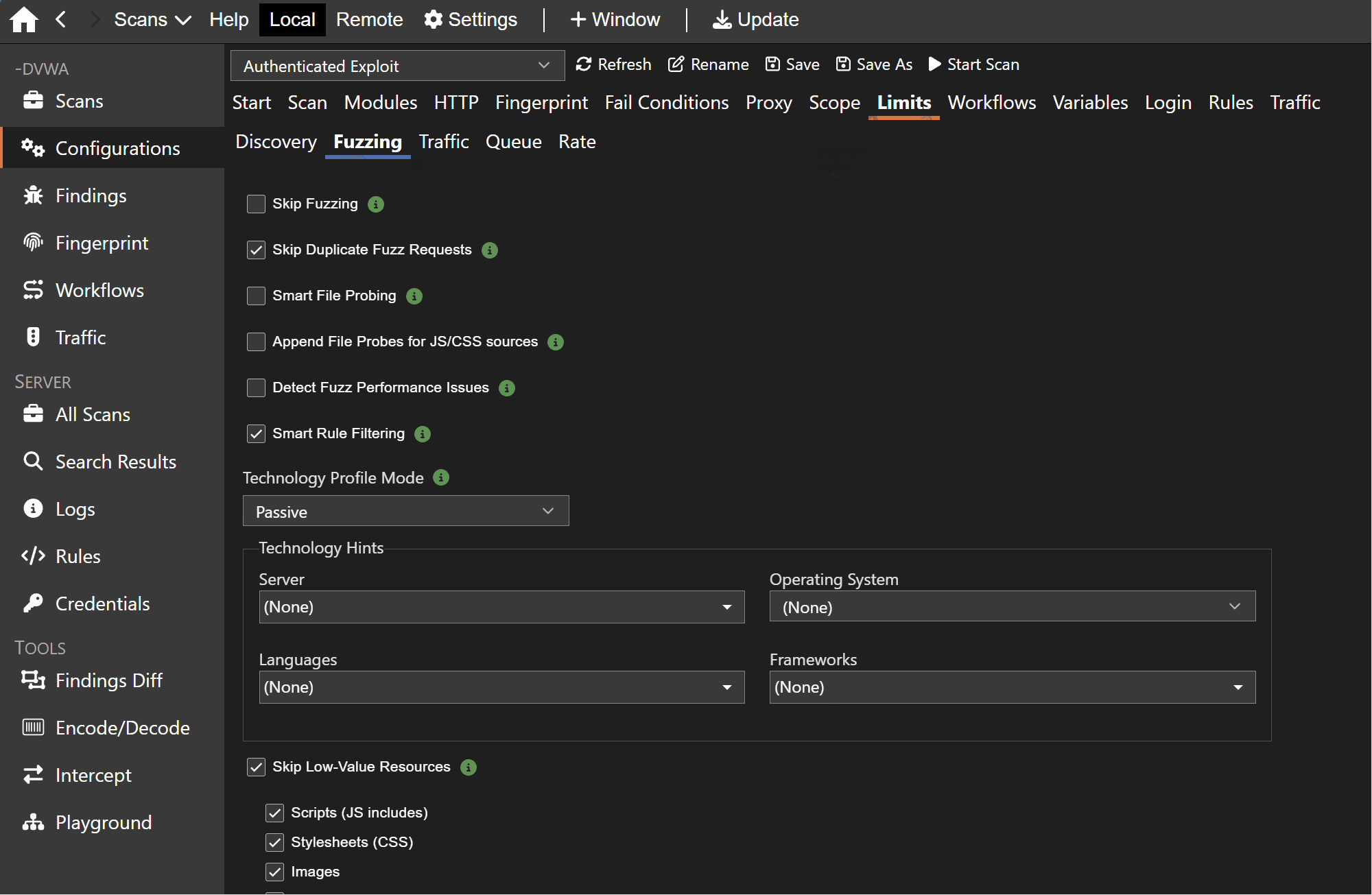
Venari now spends more of each scan on requests that are likely to produce useful security insights. Smart fuzzing identifies low-value work before it is generated, then records skipped work visibly so users can see what was intentionally avoided rather than wondering whether coverage disappeared.
- Smart Rule Filtering skips fuzzing against scripts, stylesheets, images, fonts, media, and source maps that rarely produce meaningful fuzz results, while showing those decisions as Skipped queue rows.
- Smart File Probing avoids probing directories that look inert or return soft-404 behavior.
- Staged probing and parameter affinity start with cheap universal checks, then escalate only when a parameter looks worth deeper testing.
- Non-injectable cookies such as session, CSRF, authentication, and opaque token cookies are no longer treated as useful fuzz targets.
- Duplicate JavaScript traffic is no longer re-processed as separate scan traffic when the URL and shape match.
Most of these controls are enabled by default and remain tunable. The practical effect is leaner scanning on large, resource-heavy applications while preserving the checks that are most likely to find real issues.
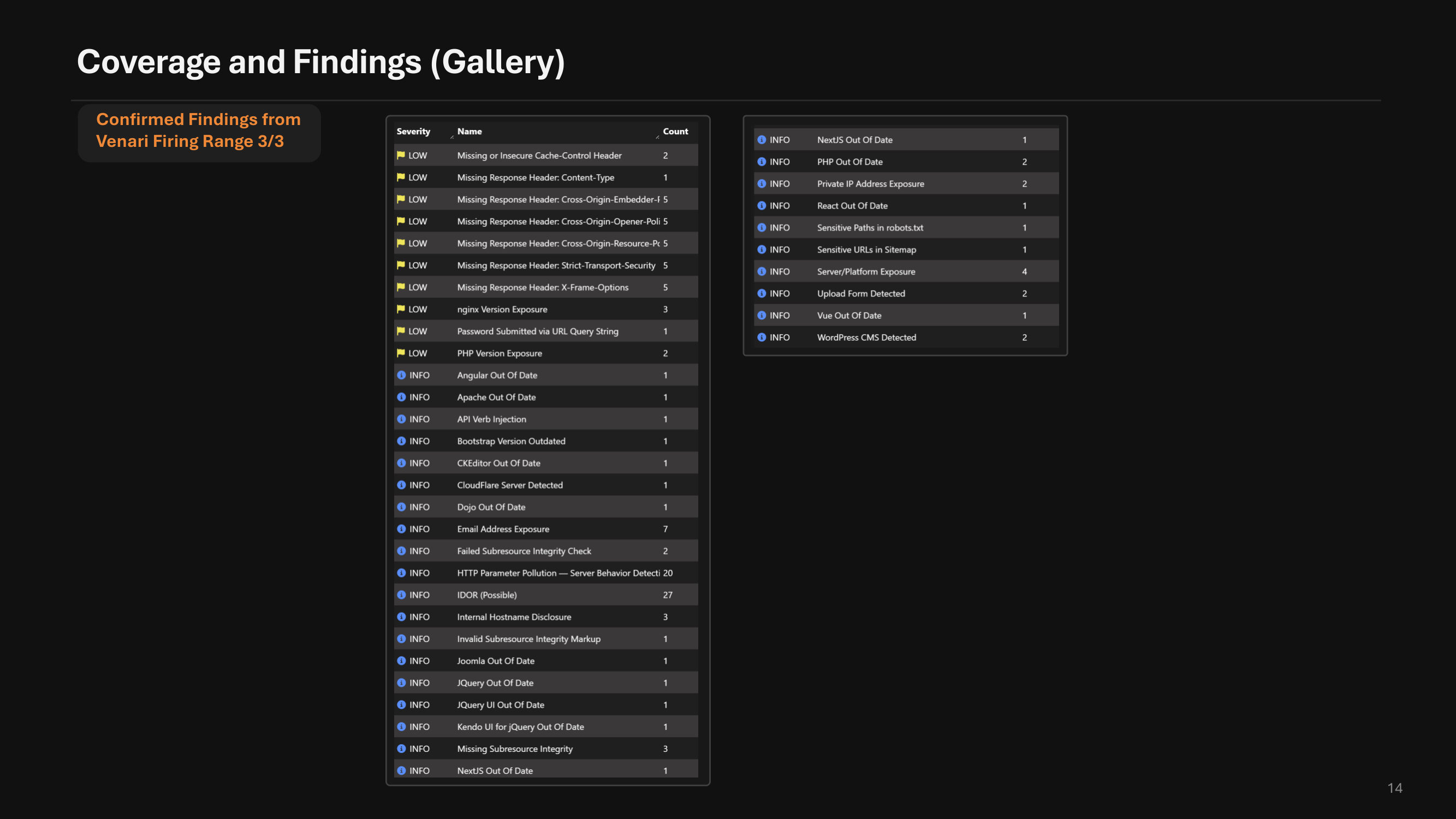
Expanded AppSec Rule Library (and Venari Firing Range)
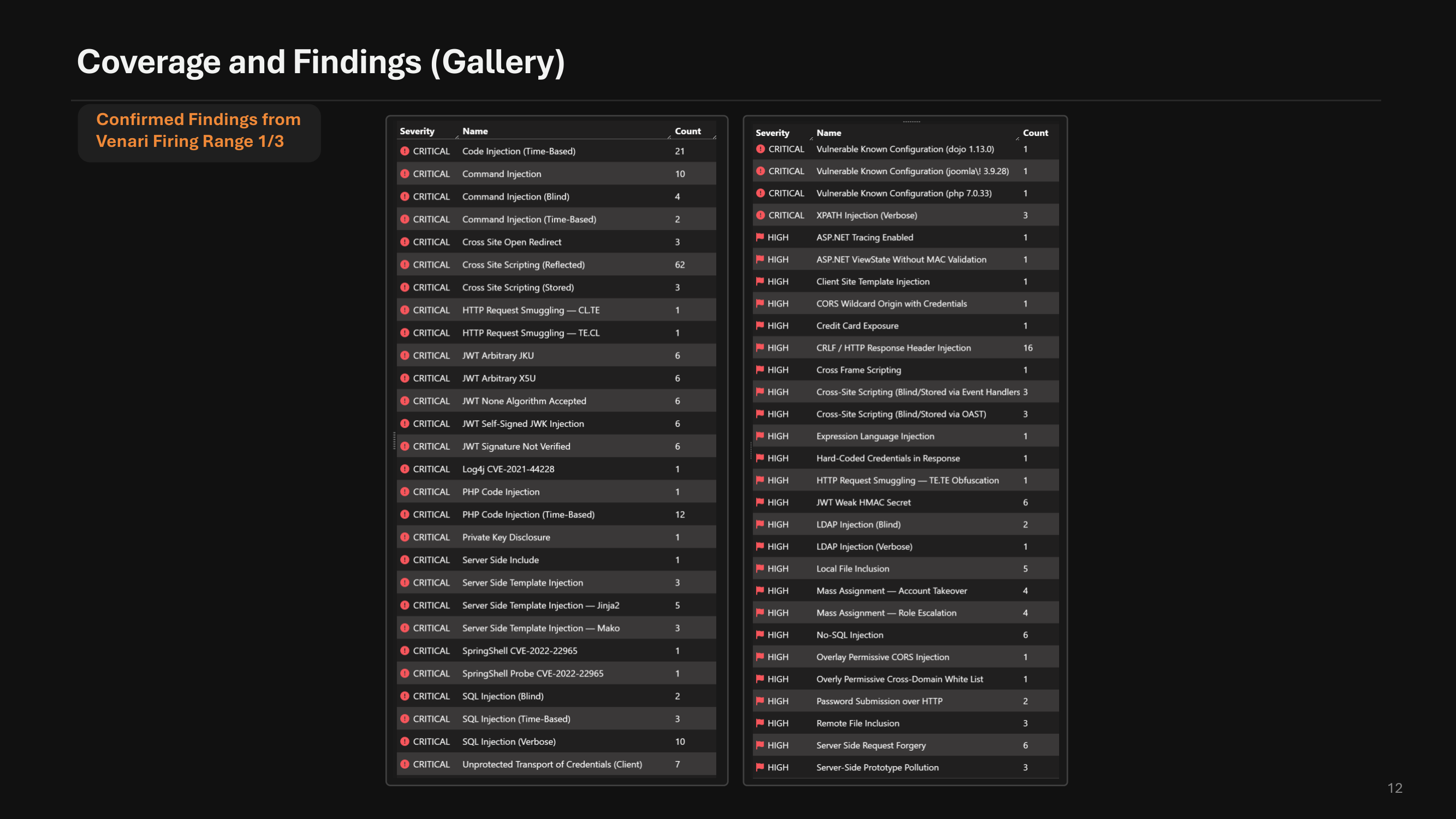
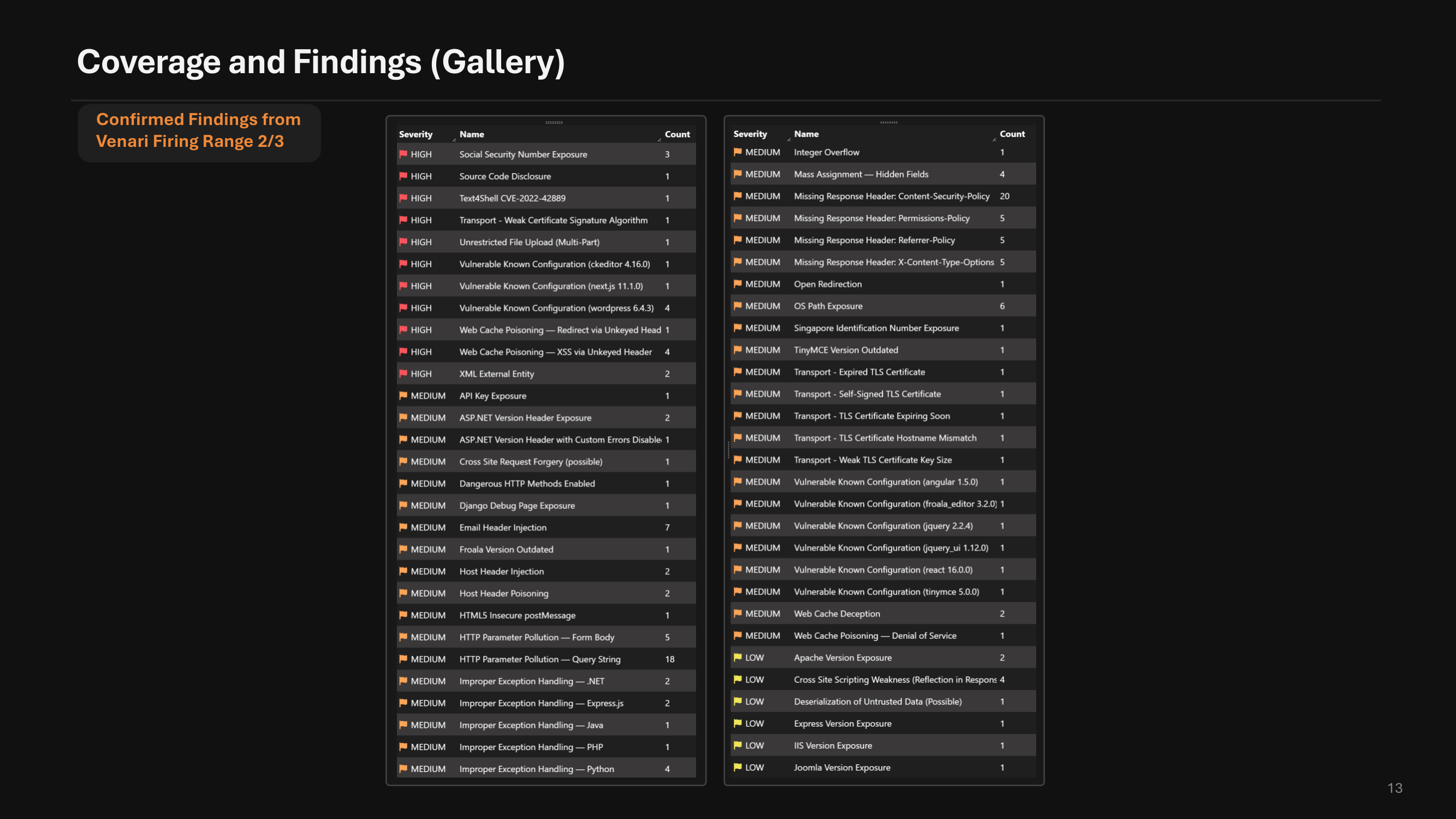
6.1 delivers the largest detection-coverage expansion in Venari's history. The expanded rule library adds or improves coverage for CRLF injection, expression-language injection, integer overflow, open redirection, SSRF, server-side template injection including Jinja2 and Mako, XPath injection, blind and stored XSS, SSI, RFI, CSRF, IDOR, API verb tampering, and reworked command, NoSQL, LDAP, LFI, and XXE detection.
The new rule evaluation engine improves how Venari collects evidence, evaluates timing behavior, and applies the right matching strategy for different kinds of findings. That gives the rule library more room to grow without turning every new check into scan noise.
Every rule is validated against the Venari Firing Range, a purpose-built set of vulnerable applications and endpoints. New rules do not ship until they prove themselves on the range — for both true-positive coverage and false-positive resistance. That discipline is how 6.1 can expand coverage this aggressively while reducing finding noise. The HTTP CVE rule set has also been refreshed for 2024 and 2025 disclosures. A new rule detects the 2026 TanStack / getsession.org npm supply-chain compromise in served JavaScript.


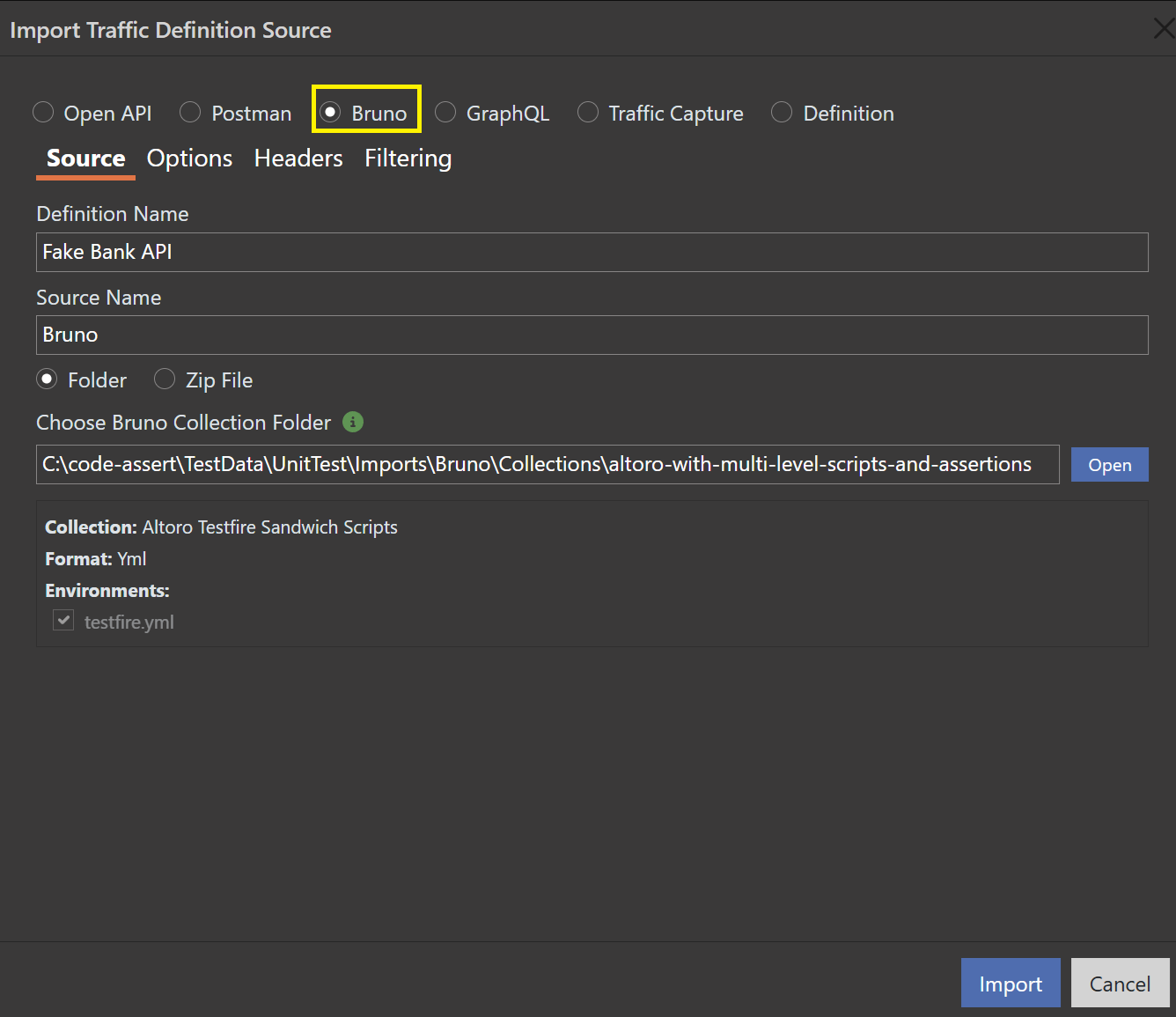
Bruno Collection Import
Teams that test API behavior using Bruno collections can now import those collections into Venari as traffic definitions. 6.1 imports both modern Bruno collection files and the legacy .bru DSL from a ZIP upload, preserving folder structure, variables, authentication, and request scripting.
The import path includes a JavaScript sandbox for pre-request and post-request scripts, so Bruno collections can behave much more like the API workflow your team already uses. For AppSec teams, that means faster onboarding of API coverage and less duplicated work maintaining separate scanner-only traffic definitions.
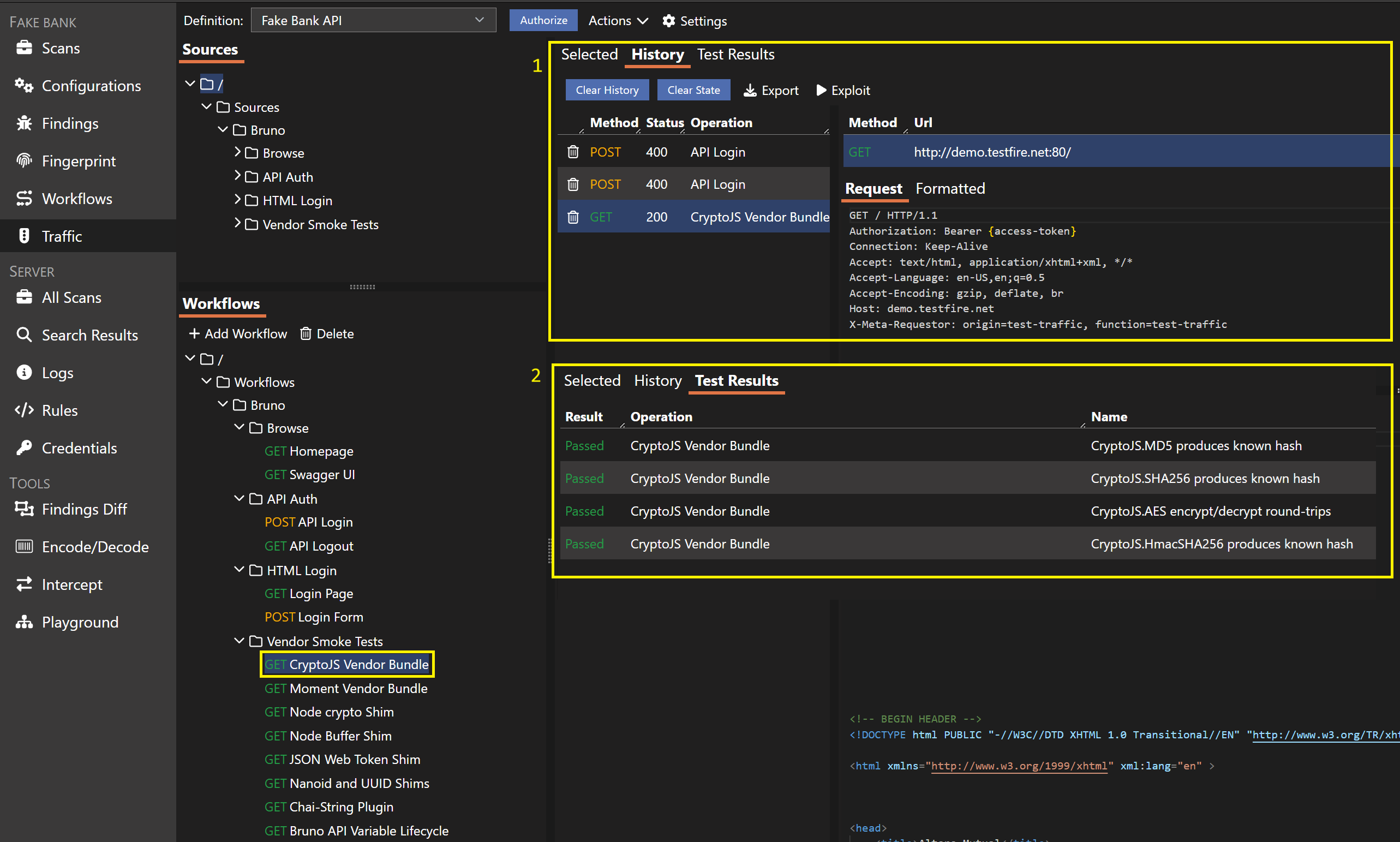
ServiceNow Scoped-App Scanning
Venari can now onboard and scan ServiceNow scoped applications from a source bundle. Instead of forcing teams to manually recreate traffic, Venari parses the scoped-app source, synthesizes scan traffic, and exposes the workflow directly in the New App Wizard.
ServiceNow-specific rules and optimizer tuning make the resulting scans more relevant to the platform, with cleaner coverage for scoped-app attack surface and less noise from inspect/fuzz rules that do not apply.
New Attack Engines: JWT, Web Cache, Request Smuggling
Three new attack engines extend Venari into vulnerability classes that require specialized request handling and evidence collection. Each engine is built to add depth where the application requires it, without inflating every scan with unnecessary work.
| Engine | Detects |
|---|---|
| JWT attack engine | JSON Web Token weaknesses such as algorithm confusion and key injection, including arbitrary JKU cases. |
| Web cache poisoning & deception | Cache-poisoning issues such as XSS, redirect, and denial of service, plus cache-deception vulnerabilities driven by cache-behavior profiling. |
| HTTP request smuggling | CL.TE, TE.CL, and TE.TE desync conditions, along with HTTP parameter pollution. |
Each engine has dedicated rules and Venari Firing Range coverage, so the findings derive from targeted evidence.
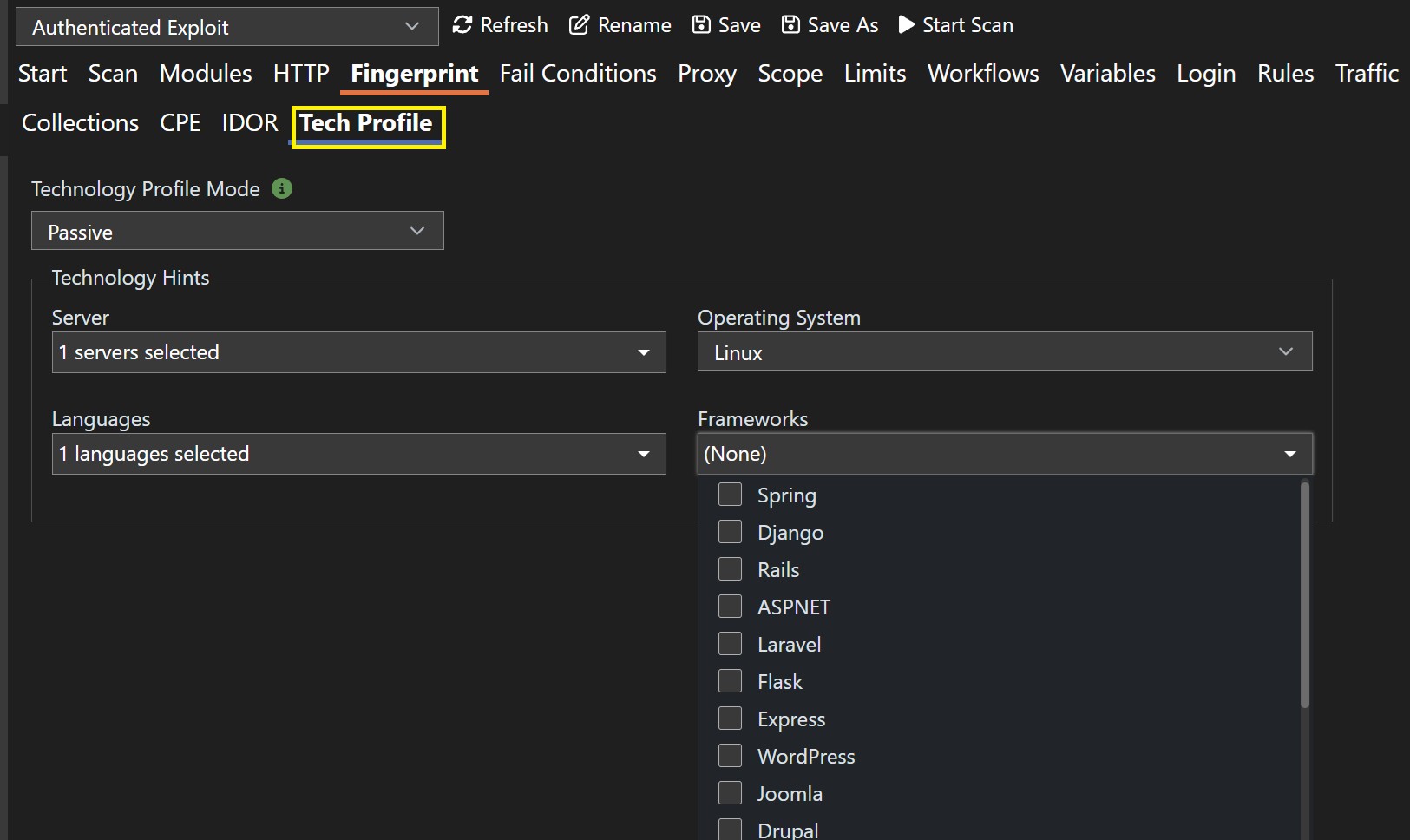
Tech-Stack Fingerprinting & Rule Targeting
Venari now actively fingerprints the technology behind an application before deciding which checks to emphasize. Error-page signatures, known-path probes, and responses to malformed requests help build a technology profile that scopes rules to the stack actually in use.
That means scans spend less time on irrelevant checks and findings carry better platform context. A PHP target, for example, does not need the same rule mix as a .NET target. Venari 6.1 uses the detected (or manually input) profile to make that distinction automatically.
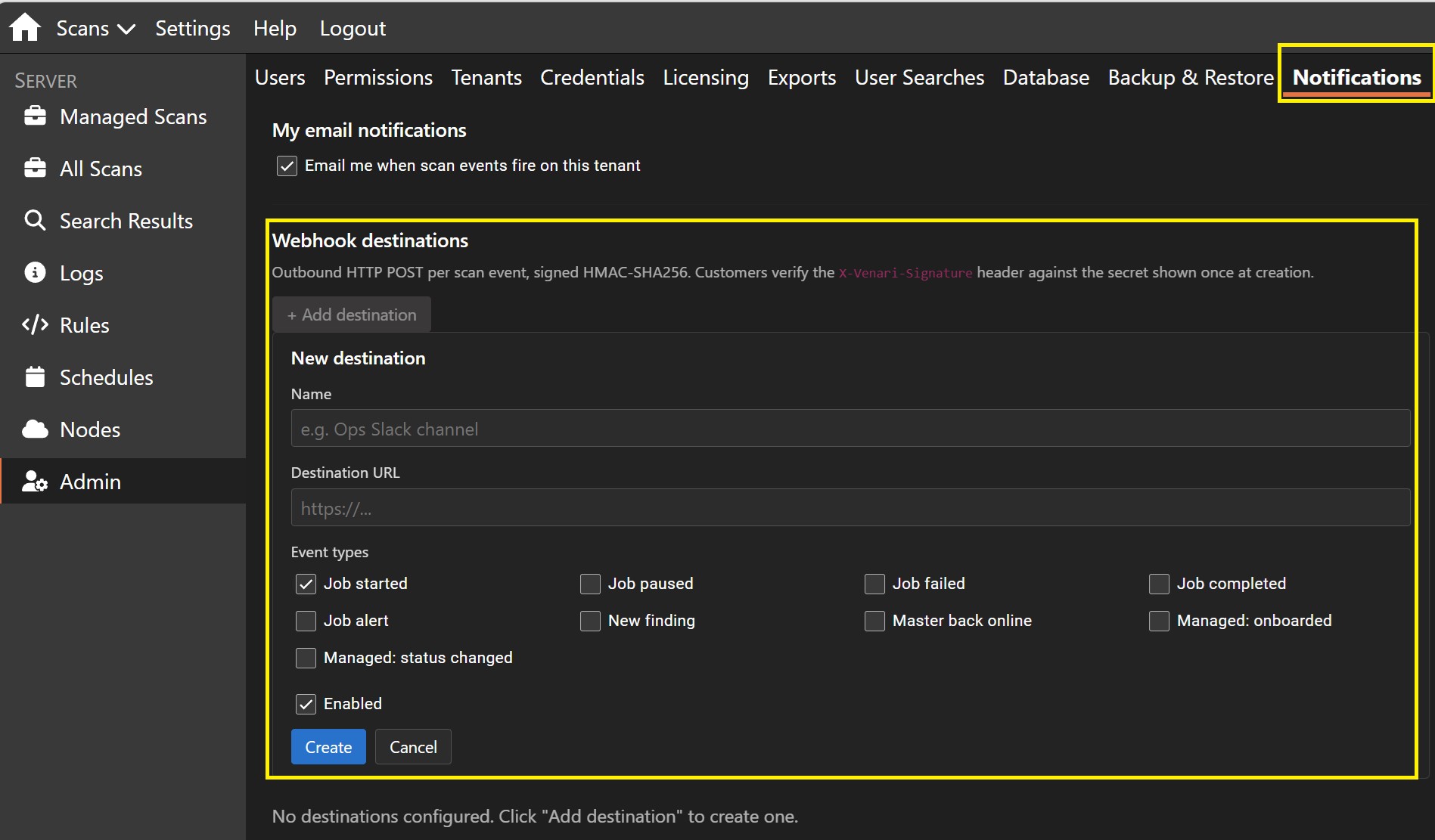
Scan Notifications — Email, Webhooks, Per-User Subscriptions
Venari can now deliver scan-event notifications by webhook and email, and fan a single event out to multiple destinations at once. Existing webhook integrations keep working by default.
Teams can opt into HMAC-signed multi-destination delivery, per-user scan-event subscriptions, and admin-managed email subscriptions. That makes it easier to route scan events to security operations, engineering owners, and workflow automation.
Browser Engine Refresh & 'Full Browser' option for Bot-Blocking Sites
The embedded browser has been upgraded to Chromium 147 with matching Client Hints, and improved page-load readiness detection that helps Venari wait for modern single-page applications to finish page rendering before reading content. The result is more reliable crawling, better authenticated coverage, and fewer page misses due to premature DOM snapshots.
6.1 also adds a Full Browser option for sites that block automated crawling. By default Venari drives a lightweight headless shell — fast and efficient, but a stripped-down browser build that some bot-detection algorithms fingerprint and reject. Full Browser mode runs the complete Chrome/Chromium browser instead — still headless, but presenting the fingerprint and behavior of a genuine browser — with anti-automation stealth measures.
Substantial False Positive Reduction
6.1 puts significant work into making findings easier to trust. The headline change is a mid-scan isolated re-test for timing-based rules: when a timing finding looks promising, Venari pauses competing scan activity, waits for the target to settle, and reruns the full sequence with a paired control before confirming the issue.
SQL injection and blind SQL injection accuracy have also been tightened. WAF-bypass behavior is now part of the core SQLi rule and only fires when WAF interference is detected, while blind SQLi adds self-stability and dialect checks to avoid erratic wrong-dialect reports. A broader cleanup pass reduces noise across credential, API-key, open-redirect, HPP, cache, and command-injection rules.
Findings are also cleaner at the reporting layer: inspection findings can be de-duplicated by unique value, so the same exposed email address or key is not reported repeatedly, and stable finding identity improves cross-scan comparison and regression triage.
Lower Memory Footprint
Large scans are less likely to be limited by memory in 6.1. Venari now uses far less memory in hot paths that previously created excessive allocation and garbage collection pressure.
For customers running bigger applications or memory-constrained scan nodes, the practical benefit is more headroom: fewer scans slowed by memory pressure and more predictable performance during large scans.
Modernized UI & Interface Polish
The Venari interface has been moved forward onto newer Angular, Bootstrap, and Electron foundations, with polish across tables, dialogs, and controls. The result is a cleaner product experience on the UI.
6.1 also adds a queue Activity time-range filter, making large scan queues easier to review when teams need to focus on a specific window of work.
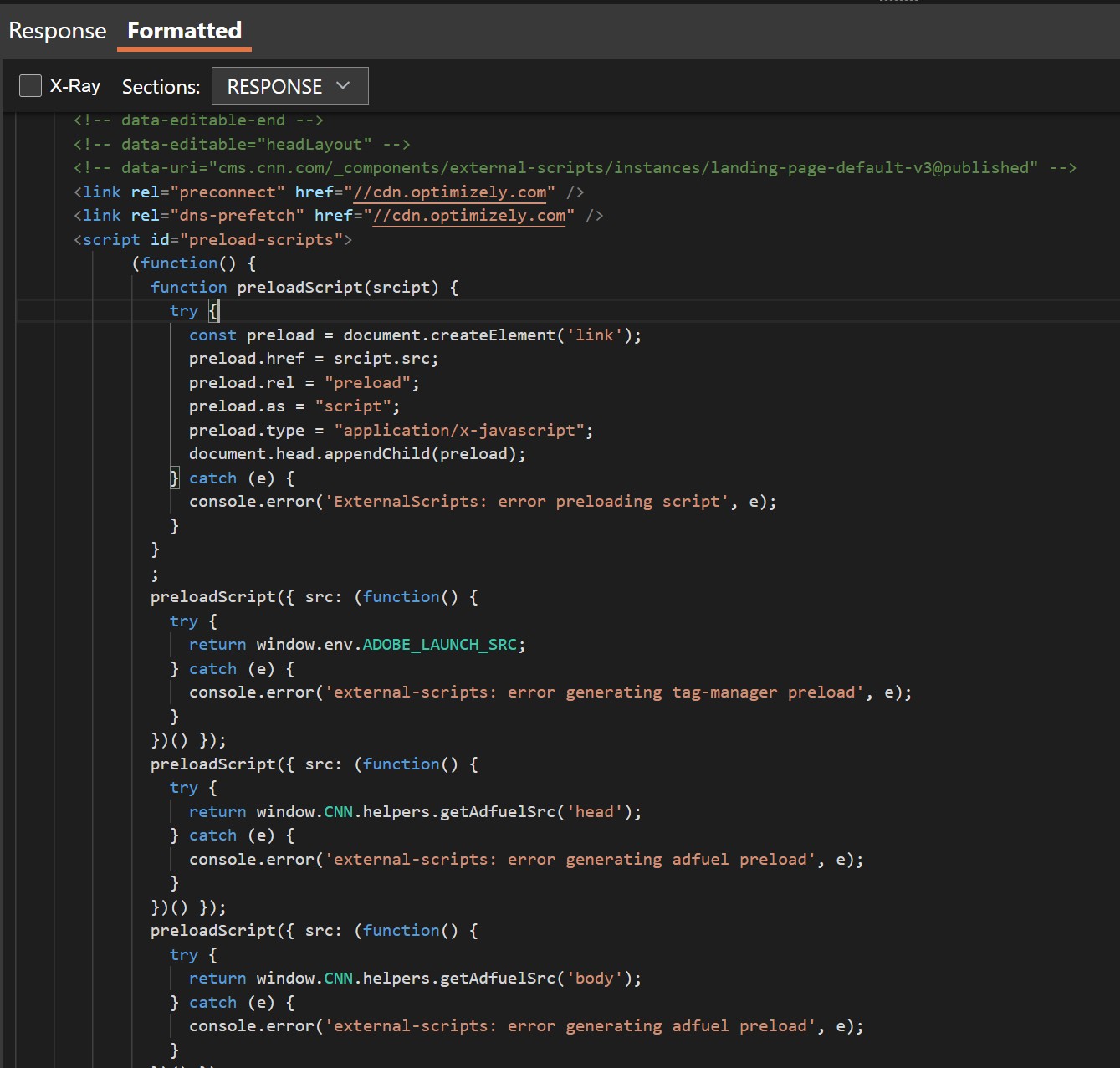
JavaScript and HTML also render more cleanly in traffic and response views, now beautified via a single, AST-based formatter — including inline <script> blocks inside an HTML document. Embedded JavaScript is formatted for easy review, instead of being rendered as minified, single-line representations.
Beautified HTML with inline JavaScript
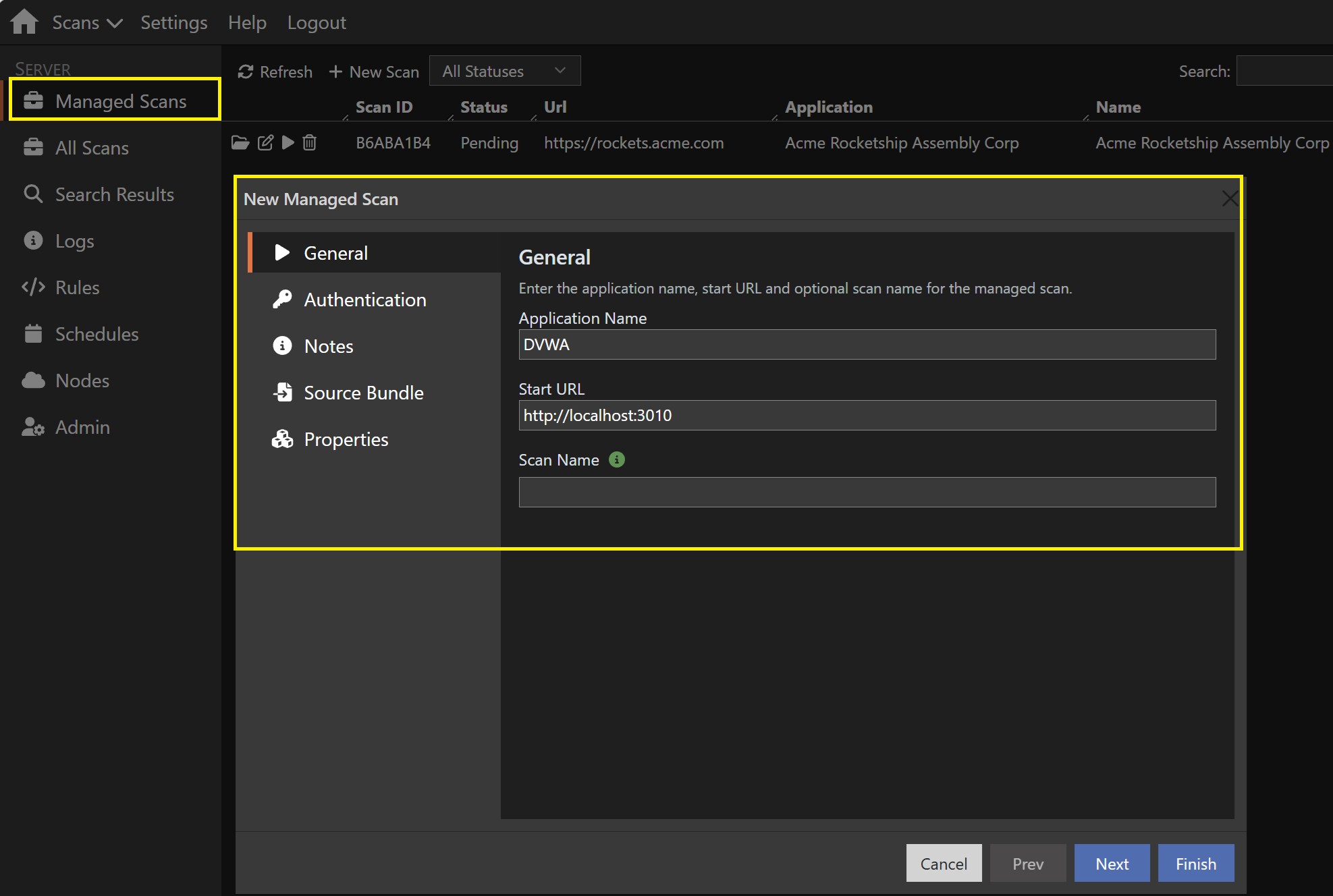
Managed Scans — Simplified SaaS Onboarding
Managed Scans are a Venari SaaS feature that streamlines customer onboarding and everyday use. Rather than configuring and operating the full scan pipeline, a customer onboards a managed scan through a simplified UI and lets Venari take care of the rest.
Behind the scenes, Venari runs the real, full-fidelity scans under the covers and correlates each final scan result back to the managed scan the customer onboarded. The customer gets a focused, low-friction experience while still receiving complete Venari scan coverage and findings.
Customer-Hosted Scan Nodes
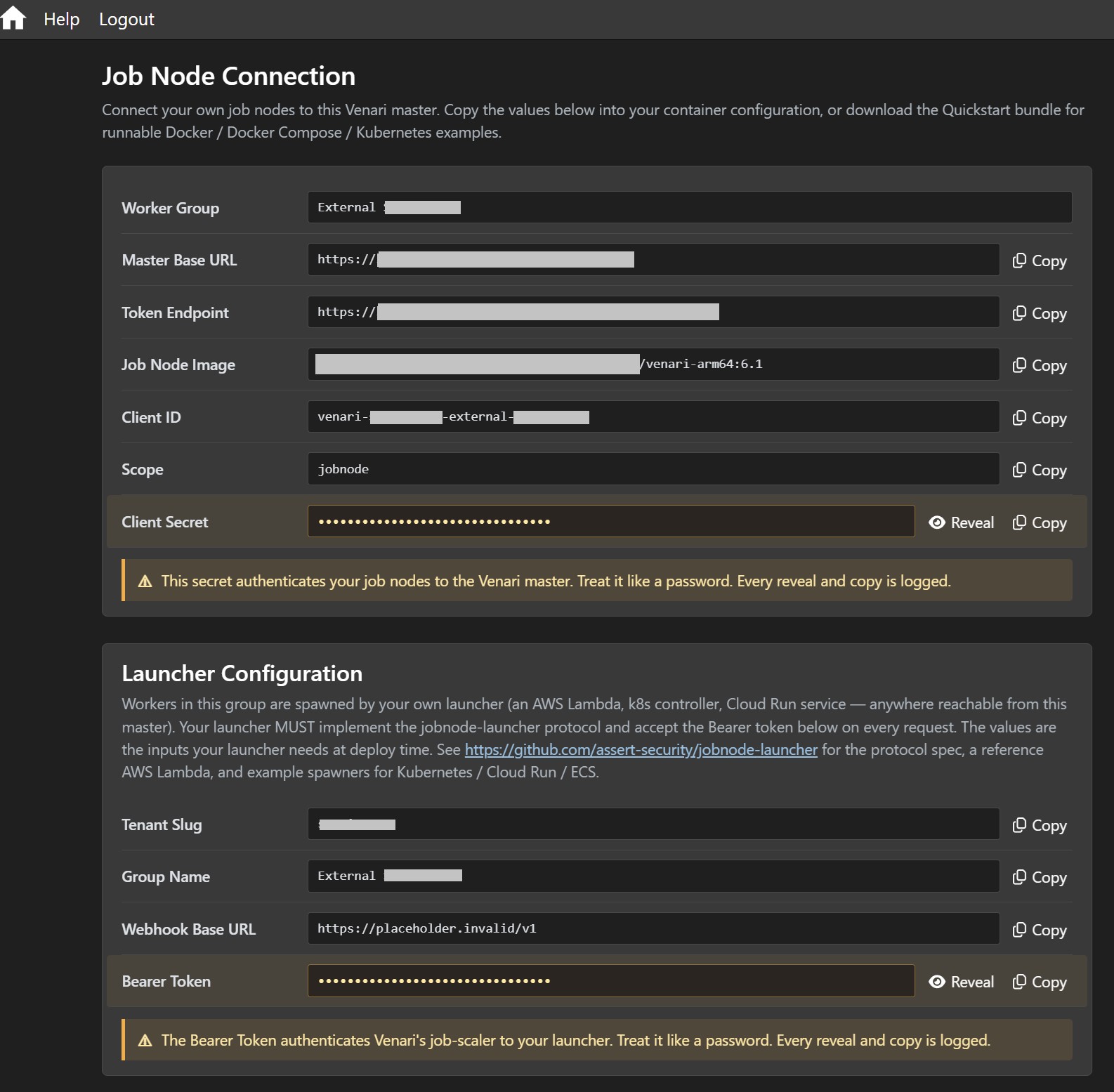
Cloud customers can now run scan workers in their own environment while still managing work from the Venari SaaS master. That lets scans execute where the target network is reachable and where data-residency or capacity requirements make the most sense.
Jobs and users can be routed to specific worker groups, giving administrators control over which workers handle which scan workloads. A customer-facing Connection page provides a downloadable connection bundle and copy-paste Quickstart examples for Docker, Docker Compose, and Kubernetes.
Job Node Connection page and downloadable bundle
ARM64 Linux Scan Nodes (incl. AWS Graviton)
Venari's Linux scan-node container now runs natively on ARM64 (Ubuntu), not just x86-64. This allows scanning on ARM cloud compute such as AWS Graviton — typically lower cost and more power-efficient than comparable x86 instances — so large or always-on scanning fleets run at lower cost.
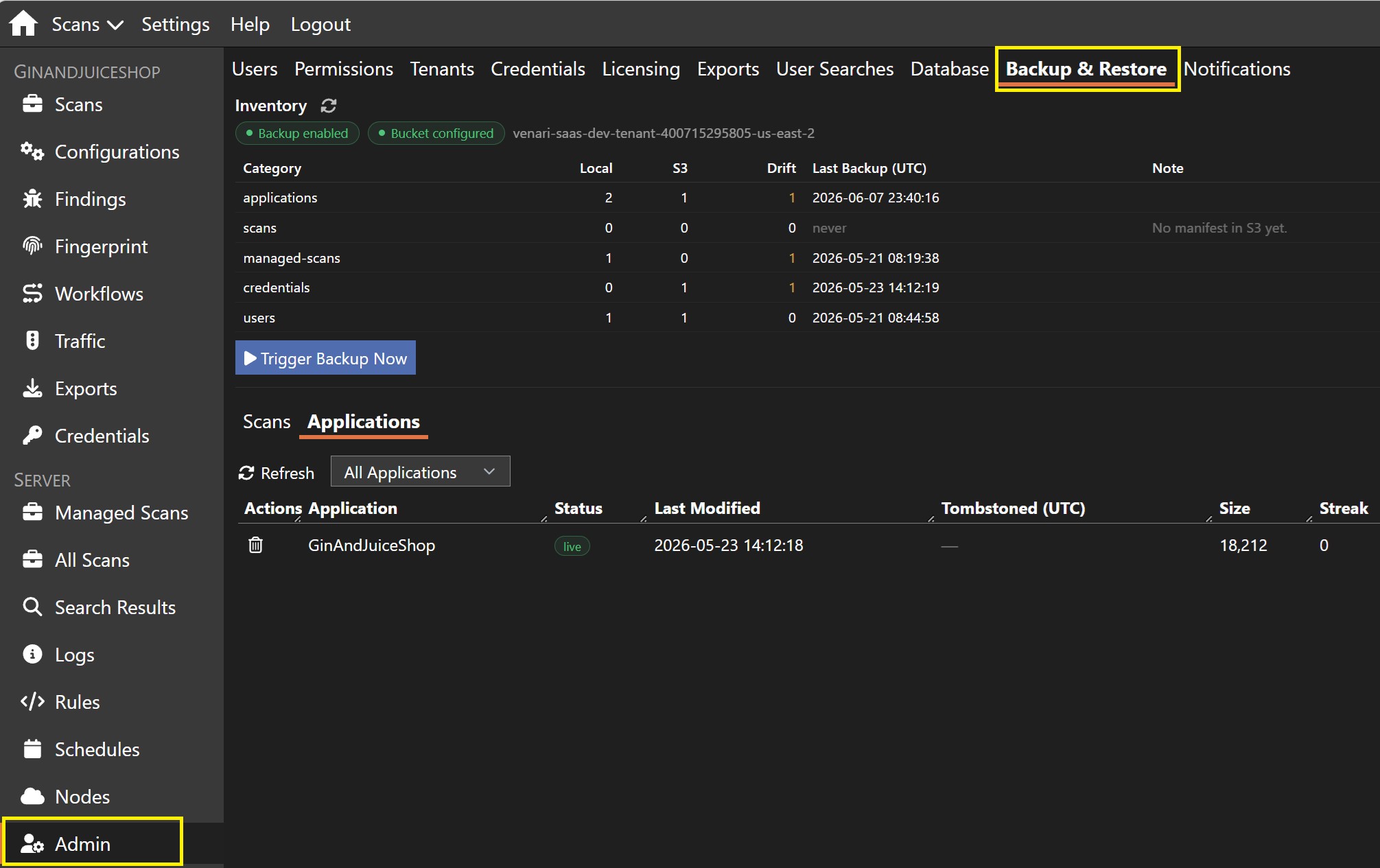
Durable Cloud Backup & Restore
Venari SaaS deployments now back up scan data, findings, and configuration durably to Amazon S3, with per-tenant encryption, retention locking, and support for large objects. Customer scan history stays recoverable without turning restore into a long outage.
Restore is designed to bring the most useful data back first. On startup, a master serves vital data before the bulk restore continues in the background, with a visible status banner and counts that fill in as applications return. Direct-scan customers also get self-service scan restore: archived scans appear as placeholder rows and restore on demand when opened or exported.
Enterprise Multi-Tenancy & SSO
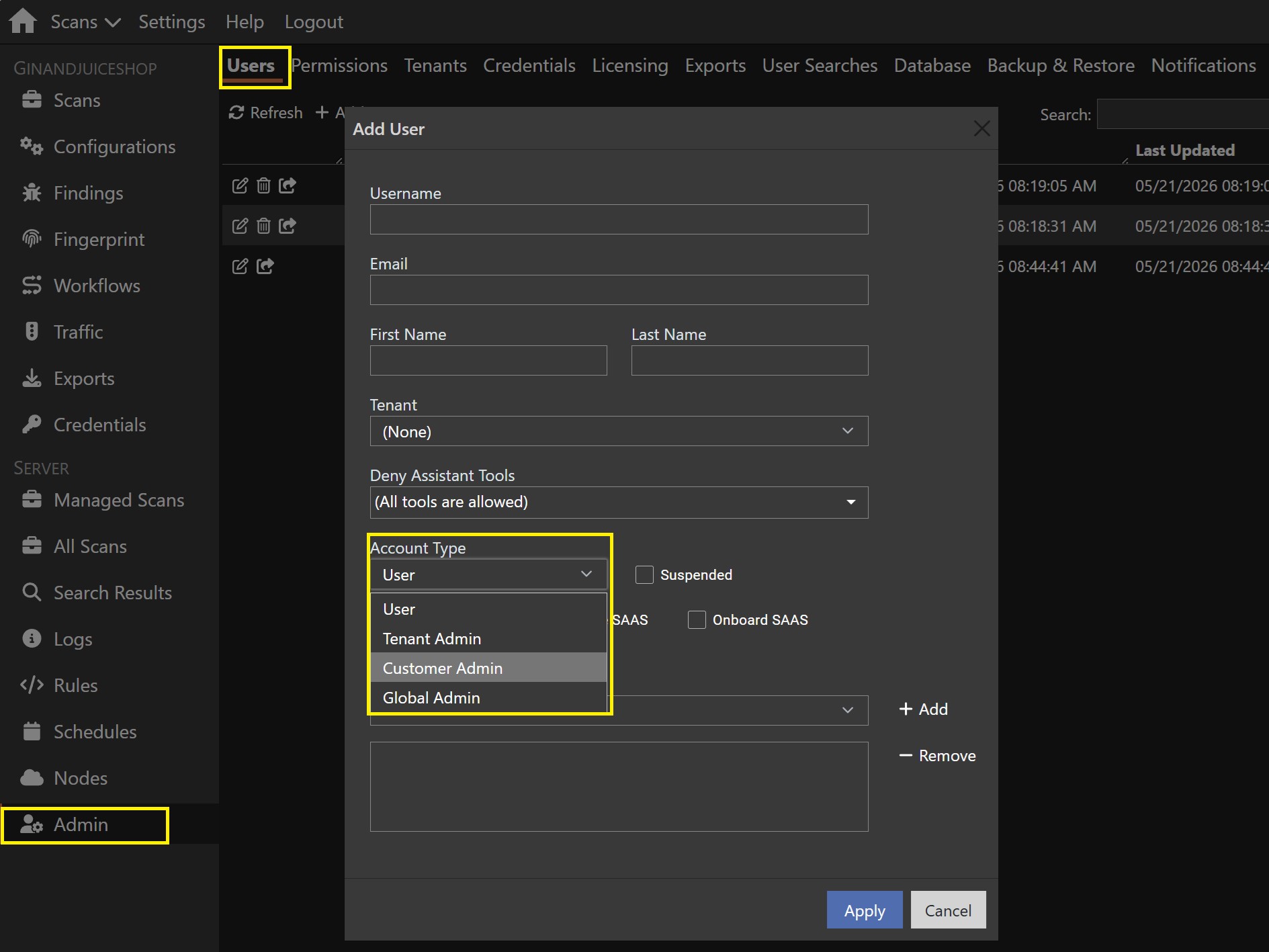
6.1 expands Venari's enterprise administration model for customers running multiple tenants, teams, or delegated admin boundaries. Tenant-admin controls are tightened, customer-admin enforcement is clearer, and a cross-tenant data role lets approved users read across tenants without granting broad administrative power.
Single sign-on through an external identity provider (Auth0) enforces role and tenant claims during token validation. Just-in-time provisioning, invitation workflows, and per-user DevOps API keys give administrators stronger control over who can sign in, what they can access, and how automation is scoped.
Change Log Summary
The list below is a technical companion to the release notes. This summary covers the broader set of changes to the engine, rules, browser/parsing stack, cloud, performance, and the infrastructure behind them. The list is a representative summary of important code changes, not an exhaustive commit log.
Added
Detection — new attack engines & rules
- JWT attack engine: JSON Web Token fuzzing with dedicated rules for algorithm confusion, key injection, arbitrary JKU, and firing-range coverage.
Adds targeted coverage for token-based auth weaknesses that generic request fuzzing can miss. - Web cache poisoning & deception engine: cache behavior profiling with rules for cache poisoning (XSS, redirect, DoS) and cache deception.
Finds cache-specific vulnerabilities by first understanding how the target actually caches responses. - HTTP request smuggling engine: CL.TE / TE.CL / TE.TE desync detection plus HTTP parameter pollution (HPP), built on a raw-HTTP client and probe builder.
Extends scanning into desynchronization classes that require precise low-level request handling. - New rule evaluation engine: pluggable match handlers (HTML/URL/CVE/sleep/cached-results), evidence builder, baseline timing collector, and YAML rule parser underpinning the expanded library.
Gives new and existing rules a stronger, more consistent foundation for evidence and confirmation. - Major rule-library expansion: new/expanded coverage for CRLF, expression-language injection, integer overflow, open redirection, SSRF, SSTI (incl. Jinja2/Mako), XPath injection, blind/stored XSS, SSI, RFI, CSRF, IDOR, API verb tampering, and reworked command, NoSQL, LDAP, LFI, and XXE detection.
Broadens vulnerability coverage across more bug classes without requiring separate scanner setup. - Active technology fingerprinting: error-page, known-path, and malformed-request probes build a technology profile that scopes which rules run.
Runs more relevant checks for the application stack and avoids wasting scan time on mismatched rules. - OAST / blind-vulnerability infrastructure: out-of-band testing job config and blind-XSS/OAST groundwork, plus compliance taxonomy/framework contracts.
Lays the product foundation for blind and out-of-band findings that cannot be confirmed from the immediate response alone. - TanStack / getsession.org supply-chain rule: detects the 2026 npm campaign IoCs in served inline scripts and JS bundles.
Flags served JavaScript that matches known compromise indicators before it reaches users unnoticed. - HTTP CVE rule refresh: detection templates added/updated for 2024 and 2025 disclosures.
Keeps the scanner current against newer public vulnerability disclosures in HTTP-accessible software. - HTML container-limit rule auto-generator: synthesizes limit rules from DOM snapshots to tame over-discovery on data-grid/list-heavy SPAs.
Improves crawl control on modern SPAs that can otherwise explode into repetitive low-value paths. - ServiceNow detection rules: new rules for unauthenticated
.dopages and a main-content iframe-whitelist limit, with Jelly-XSS false-positive fixes.
Sharper, quieter coverage tuned to the ServiceNow platform.
Scan engine & fuzzing
- Adaptive per-origin concurrency (AIMD): self-tuning request and browser-pool concurrency with congestion back-off, requeue, a resizable per-origin gate, cross-lane overload brake, live dashboard, and General-tab toggle.
Scans run as fast as each target can handle and back off automatically instead of wedging under load. - Smart Rule Filtering: skips fuzz/Nuclei rule generation against low-value resources (scripts, styles, images, fonts, media, source maps), with each skipped item surfaced as a Skipped queue row.
Cuts request volume on resource-heavy sites while keeping skipped work visible to the operator. - Smart File Probing: soft-404 / directory-shape gating with a verdict cache to suppress probes on inert directories, plus a FileProbeMode setting and UI limits control.
Avoids spending scan time on directory probes that are unlikely to produce useful findings. - LFI staged probing + parameter-affinity tiering: cheap universal probes run first, and the full payload matrix is gated by an interest check with Smart/Balanced/Exhaustive tiers (default Smart).
Reserves expensive LFI testing for promising parameters while preserving deeper testing where signals justify it. - Cookie fuzz gating: skips framework/session/CSRF/auth and opaque-token cookies that are never injectable application data.
Removes noisy, low-value cookie targets from fuzzing without hiding meaningful application input. - Technology-profile rule filtering: runs only rules relevant to the detected stack, with settings and UI to supply profile hints.
Focuses scans on the vulnerabilities that make sense for the target technology. - Mid-scan isolated retest for timing rules: re-runs a time-based finding in isolation under quiescence, with a paired control, before confirming.
Suppresses timing false positives caused by scan load or transient target slowness. - Per-analysis-item wall-clock budget: bounds the time any single item can consume.
Stops one pathological target or rule path from dominating the scan schedule. - Smart-fuzz orchestration & per-endpoint profiling: profiles fuzzing per endpoint and reports skipped vs. executed rules.
Shows what was and wasn't fuzzed on each endpoint, so coverage decisions are visible.
Onboarding & traffic import
- Bruno collection import: ingests modern and legacy
.brucollections via ZIP, preserving folder structure, variables, and auth, with a built-in JavaScript sandbox for pre/post-request scripts.
Lets teams bring Bruno API collections into Venari with the context needed for realistic API scanning. - ServiceNow scoped-app onboarding: Jelly source parser, deterministic traffic synthesizer, server import endpoint, and New App Wizard source option.
Turns a ServiceNow scoped-app export into scanable traffic without hand-building the app map. - Managed Scans (SaaS): simplified SaaS onboarding where a customer onboards a managed scan through a streamlined UI while Venari runs the real scans under the covers and correlates each final scan back to the managed scan.
Gives SaaS customers a low-friction onboarding and scanning experience without exposing the full scan pipeline.
Cloud / SaaS / multi-tenancy
- S3 backup-restore subsystem: durable backup of scans, findings, and config to S3 with per-tenant CMK encryption, object-lock retention, multipart upload (>5GB), tombstone propagation, scan auto-backup, and per-finding incremental backup.
Improves durability and recoverability for cloud scan data without giving up tenant isolation controls. - Boot-time serve-then-restore: masters serve vital data before bulk restore runs in the background, with recency-prioritized apps, lazy findings restore, and an SPA restore-status banner.
Gets the service usable sooner after startup while long-running restore work continues safely behind the scenes. - Self-service scan restore: archived scans appear as placeholder rows and restore on open/export for opt-in direct-scan tenants.
Restores archived scan results on demand instead of depending on manual support intervention. - Hybrid Job Nodes: customer-run scan workers with worker-group routing, a Connection page, downloadable connection bundle, and Docker/Compose/Kubernetes Quickstart.
Allows customers to run scanning capacity in their own environment while still managing work from Venari. - Notification fan-out: opt-in multi-destination HMAC-signed notifications plus SES email, per-user scan-event and email subscriptions, with the legacy webhook preserved by default.
Sends scan events to more of the systems and people that need them without breaking existing integrations. - Multi-tenant admin roles + cross-tenant data role: tiered administration with tenant-admin lockdown and a non-admin read-across-tenants role.
Supports larger enterprise administration models with clearer separation of tenant and cross-tenant duties. - External IDP (Auth0) SSO: role/tenant-claim enforcement at token validation, JIT provisioning, invitation workflow, and bearer-token routing by issuer.
Aligns Venari access with external identity governance while preserving tenant boundaries. - Per-user DevOps API keys: resolved from SSM bootstrap config with a reveal flow and tenant-scoping.
Gives automation a user-scoped credential path instead of relying on shared or loosely scoped keys.
Browser & deployment
- Full Browser Mode: scan setting (Off / login workflows only / entire scan) that launches full Chromium with anti-automation stealth flags.
Extends coverage to applications that need a real browser path beyond login alone. - ARM64 Ubuntu support: includes Tesseract OCR on ARM64.
Expands supported deployment options for teams standardizing on ARM64 Linux environments. - Job queue Activity time-range filter: per-row filter on the edit-queue-detail view.
Simplifies inspecting queue activity for the time window that matters during scan review.
Changed & Improved
- Scan reliability: browser pool detects Chrome crashes / CDP navigate timeouts and recovers; master self-heals a corrupted identity/NodeInfo database on startup; master exposes an idle-shutdown signal.
Long-running and unattended scans are less likely to stall, require manual repair, or waste idle cloud resources. - SQL injection: all SQLi rules chained; WAF-bypass capability folded into the core rule and gated behind WAF-interference detection.
Preserves deeper SQLi testing where a WAF is interfering without bloating every scan path. - SSTI: consolidated rules with technology-affinity payloads, covering previously unsupported template engines.
Broadens server-side template injection coverage while targeting payloads to the likely engine. - Finding identity & dedup: stable per-finding
CompareUniqueIDfor cross-scan diff; unique-value gating so duplicate matches are not re-reported.
Cleans up regression triage and stops repeated findings for the same exposed value. - Optimizer / fuzz-rule tuning: skips redundant redirect-follow/RNF probes, deprioritizes time-based/SQLi rules in the WAVSEP optimizer, applies host/port-scoped one-shot rules, and uses probe-URL fallbacks.
Trims wasted rule work while preserving the checks most likely to matter for each endpoint. - CPE keyword index: builds in the background behind an app-layer lock instead of a blocking UI dialog.
Frees scans and operators from waiting on a foreground fingerprint-index build. - Chrome traffic conversion: skips converting duplicate .js/.jsdbx/.jsx traffic when URL/shape matches.
Cuts redundant processing on JavaScript-heavy applications. - Browser engine: Chromium upgraded 144 → 147 with matching Client Hints/user-agent; ScriptEngine → BrowserClient automation stack with content-readiness (DOM-maturity/LCP/networkidle) detection.
Modernizes browser-driven scanning and improves readiness decisions on dynamic pages. - Custom headers: support URL wildcard patterns with robust base64/encoding handling.
Handles header configuration more flexibly and robustly across encoded or pattern-matched traffic. - JavaScript analysis: unified analysis with AST/text parse-mode overrides, JsContentSummary facade, and hardened JS-vs-not detection.
Brings consistency and confidence to how JavaScript-like content is analyzed. - Credential resolution ledger: tracks token↔plaintext resolution and restores tokens so plaintext credentials never persist into saved templates/results.
Protects credentials while still allowing scans to use the secrets they need. - UI: Angular 14 → 19, Bootstrap 5, Electron 38 refresh with table/dialog/control polish; backup-restore admin UI on the modern datatable/checkbox; cleaner unlicensed/missing-key handling.
Refreshes the product shell and improves everyday administration workflows. - Single "Collect Instrumentation" toggle: replaces 15 per-area diagnostic toggles, default off.
Simplifies enabling diagnostic capture when support or engineering needs deeper scan data. - JS/HTML beautification: consolidated behind a single FormatUtils facade with an AST, comment-preserving formatter, retiring the legacy JSBeautifier.
Cleaner, more consistent formatting of JavaScript and HTML in traffic and response views. - JS detection & dedup: JsDetector content-confidence scoring plus token-based fuzzy hashing for HTML/JS change comparison.
More reliably distinguishes JavaScript from other content and skips near-duplicate scripts instead of re-analyzing them.
Fixed
- False positives: blind SQLi wrong-dialect reports (self-stability gate + dialect mutual-exclusion); time-based timing FPs (avg/paired-control baselines); credential, API-key, open-redirect, HPP, hardcoded-credential, cache-deception, command-blind, log4j, mass-assignment, CRLF, and email-exposure rule tightening.
Produces cleaner findings by confirming more aggressively and tightening noisy match conditions. - Rule scoping: JWT rules scoped by host:port not path; per-location fuzz limits for duplicate params; capped runaway named-expression recursion; ServiceNow jvar selector.
Prevents rule execution from spreading too broadly or recursing into low-value work. - Nuclei: fixed a matcher null-reference, runs flow-attribute templates in-tool, and resolves DSL templated expressions.
Stabilizes Nuclei-format checks imported into the Venari rule pipeline. - Scans no longer strand: Completing-state race fixed with trim before upload, finish-trim gating, and locked writes around delete.
Lets scans finish cleanly instead of getting stuck after the testing work is done. - CDP robustness: duplicate command-id, ExecuteJsAsync TOCTOU, debugger auto-resume, and expected command races quieted while real stalls still surface.
Reduces noisy browser-automation failures without masking genuine scan stalls. - HTTP connection reuse: pooled-connection reuse fixes a per-request socket leak.
Boosts stability under high request volume and lowers socket-exhaustion risk. - Browser workflows: fixed mixed HTTP + browser interaction, multi-tab/multi-browser handling, script redirect loops, fragment-URL navigation, and XSS-on-fragment behavior.
Stabilizes authenticated and script-heavy workflows during crawl and replay. - SPA / OAuth login: fail-fast on post-OAuth probe rejection, shell render for unauthenticated routes, and recovery from login-failed states.
Hardens login behavior on modern single-page applications and OAuth-backed flows. - Reporting: PDF report export on Linux containers fixed through SkiaSharp native alignment.
Restores reliable report generation in Linux-based deployments. - Discovery: definitive NotFound trap URLs are hard-skipped from browser discovery.
Avoids polluting crawl output with routes the scanner already knows are dead ends. - Scan-database integrity: fixed a TrimDatabase race that could corrupt the database, plus a B-tree index concurrency bug.
Protects stored scan data from corruption under load.
Performance
- Regex memory blowup eliminated: removed an unbounded BDD memoization cache that drove the analyzer container to ~14 GB RSS.
Large scans use far less memory and are less likely to hit container limits. - Allocation churn reduction: FastCloner deep-clone default, O(N) non-mutating named-expression expansion, and 514 MB/min churn eliminated in comparison hot paths.
Reduces GC pressure and keeps long-running analysis paths smoother. - Inspect-rule performance: faster processing of large .js/.jsdbx files, eager-shape-hash and double-hash elimination, and NoParse fast paths.
Raises throughput on applications with large or numerous JavaScript artifacts. - Thread/stack management: removed an excess worker-pool layer, set 8 MB browser-thread stacks for deep JS parsing, and fixed stranded script-engine processes.
Lowers resource contention and makes browser-backed analysis more predictable. - HtmlParser V2: span-first, low/zero-allocation WHATWG-strategy HTML parser with tokenizer, adoption-agency/foster-parenting correctness, position fidelity, fault tolerance, and legacy-parser validation.
Cuts parsing overhead while improving correctness on messy real-world HTML. - PatternMatch: span-native rewrite using FrozenSet/SearchValues/Ordinal to reduce hot-path allocation.
Speeds up repeated pattern checks in high-volume analysis paths. - SaaS init: batched category build cuts master HTTP N+1 at rule init, and host file-descriptor limit raised to avoid socket exhaustion.
Smooths SaaS startup behavior and reduces connection-limit failures under load. - Discovery traffic processing: skips processing non-leaf Chrome traffic during browser discovery (leaf actions only).
Cuts redundant per-action analysis on browser-driven crawls.
Security
- Credential leakage prevention: resolution ledger keeps resolved plaintext credentials out of saved templates and results.
Lowers the risk of secrets being persisted after they are used for scanning. - Multi-tenant authorization: tenant-admin lockdown (403 on privileged controllers), customer-admin enforcement, and workspace-query isolation.
Strengthens tenant boundaries and prevents overbroad administrative access. - SSO claim enforcement: Auth0 role + tenant-slug claims validated at the token boundary, with audit-block on elevated roles.
Ensures externally issued tokens map to the right Venari role and tenant before access is granted. - Encrypted backups: per-tenant customer-managed keys and object-lock retention on S3 backups.
Protects backed-up scan data with tenant-specific encryption and retention controls. - Dependency remediation: vulnerable NuGet packages fixed and Newtonsoft.Json consolidated to a single version.
Reduces third-party package risk and simplifies dependency management.
Infrastructure & Build
- .NET 10 platform upgrade: refreshed dependencies and Docker build modernization.
Keeps the platform current and improves the build/runtime base for future releases. - AWS licensing migration: licensing service migrated from Azure to AWS (Lambda + DynamoDB + SES + Secrets Manager/SSM) behind a staged-cutover toggle with an endpoint-parity gate.
Moves licensing onto the AWS deployment footprint while protecting cutover with parity checks. - EF migrations: user database migrations added, resolving prior schema drift.
Turns user-database upgrades into a repeatable process instead of manual schema alignment. - CPE/CVE keyword incremental backup: base+delta branching with idempotent replay and restore-then-build sync.
Simplifies safe, incremental restore of fingerprint/CVE keyword data. - Build pipeline: Jenkins on PowerShell 7 with failure propagation and code-signing fixes; AWS ECR amd64+arm64 image mirror; SBOM generation and image vulnerability scanning in CI; reliable Mac code-signing; all Complete.sln warnings cleared.
Improves release reliability, artifact coverage, and supply-chain visibility across supported platforms.
Validated on the Venari Firing Range
Detection changes in 6.1 — new engines, expanded rules, and false-positive hardening — are validated against the Venari Firing Range, our curated battery of vulnerable applications and endpoints covering each supported vulnerability class. Rules are measured for both true-positive coverage and false-positive resistance before they ship, which is how this release expands detection breadth while reducing finding noise.